Recentemente eu criei wrun, uma CLI escrita em Go que executa comandos quando há alterações no diretório atual. A abordagem usada para monitorar essas mudanças foi interagir com a API inotify do Linux. Nesse post eu irei dar uma visão geral dessa API em Go usando o package golang.org/x/sys/unix, que fornece abstrações para primitivos de SOs Unix/Unix-like.
A API
Primeiramente, você cria uma instância:
fd, err := unix.InotifyInit1(0)
O 0 representa o argumento flags. Esse argumento não será abordado aqui, mas você pode consultar a man page para saber mais sobre ele. fd é um file descriptor que nós usaremos para ler eventos, mas, antes de fazer isso, nós precisamos especificar quais arquivos/diretórios e quais eventos nós desejamos monitorar.
wd, err := unix.InotifyAddWatch(
fd,
".",
unix.IN_CREATE|
unix.IN_DELETE|
unix.IN_CLOSE_WRITE|
unix.IN_MOVED_TO|
unix.IN_MOVED_FROM|
unix.IN_MOVE_SELF,
)
Esse código significa que nós estamos monitorando 6 eventos no diretório atual. Como o nome sugere, cada vez que a função unix.InotifyAddWatch() é chamada um watch é adicionado à instância, e esse watch possui um identificador chamado watch descriptor (wd). O wd pode ser usado para remover o watch chamando unix.InotifyRmWatch().
Aqui tem alguns comandos e quais eventos eles disparam:
touch a.txt # [IN_CREATE, IN_CLOSE_WRITE]
touch b.txt # [IN_CREATE, IN_CLOSE_WRITE]
touch c.txt # [IN_CREATE, IN_CLOSE_WRITE]
mkdir dir # IN_CREATE
rm a.txt # IN_DELETE
echo cc > c.txt # IN_CLOSE_WRITE
mv b.txt dir # IN_MOVED_FROM
touch dir/d.txt
rm -r dir # IN_DELETE
mv c.txt a.txt # [IN_MOVED_FROM, IN_MOVED_TO]
mv $(pwd) ../dir2 # IN_MOVE_SELF
cd ../dir2
touch e.txt # [IN_CREATE, IN_CLOSE_WRITE]
Ao monitorar um diretório, inotify não monitora-o de maneira recursiva. Se você quiser esse comportamento, é necessário adicionar cada subdiretório à instância. Além disso, inotify é inode-based, que significa que você pode mudar a localização do arquivo/diretório passado à unix.InotifyAddWatch() e ele continuará sendo monitorado.
Quando se trata de renomear/mover um arquivo/diretório, há três eventos:
IN_MOVE_SELF: emitido quando o arquivo/diretório sendo monitorado é renomeado/movido.IN_MOVED_FROM: emitido no antigo diretório pai de um arquivo/diretório que foi renomeado/movido.IN_MOVED_TO: emitido no novo diretório pai de um arquivo/diretório que foi renomeado/movido.
Então, se você pretende associar eventos IN_MOVED_FROM com IN_MOVED_TO, você tem que levar em consideração que pode não haver um evento IN_MOVED_TO. Isso acontecerá se o arquivo/diretório foi movido para um diretório que não está sendo monitorado. Uma das soluções para isso é criar um timer (e.g. time.After()). Se um IN_MOVED_TO não for emitido antes de o timer expirar, considere que o arquivo/diretório foi movido para um local não monitorado. Por último, já que esses eventos não são necessariamente sequenciais, cada um deles contém um valor cookie que os relaciona.
Lendo eventos
Eventos são lidos chamando a função unix.Read() com o fd da instância. Além de um file descriptor, essa função também necessita de um buffer para armazenar os eventos.
var buff [unix.SizeofInotifyEvent + unix.NAME_MAX + 1]byte
n, err := unix.Read(fd, buff[:])
A constante unix.SizeofInotifyEvent é o tamanho de inotify_event, um struct C que representa um evento. A parte unix.NAME_MAX + 1 é relacionada a esse struct conter um flexible array member. Um campo desse tipo fica localizado no fim do struct, tem um tamanho dinâmico e é ignorado ao calcular o tamanho do struct (unix.SizeofInotifyEvent). Esse é o campo que representa o nome de um arquivo/diretório. unix.NAME_MAX representa o tamanho máximo de um nome de arquivo/diretório, e + 1 tem a ver com essa constante não incluir o caractere NULL presente no fim de uma string C. Portanto, esse tamanho garante que o buffer será capaz de armazenar pelo menos um evento.
Agora nós precisamos converter os bytes em buff em um ou mais unix.InotifyEvent, que é o equivalente ao struct inotify_event. O problema com essa conversão é o valor de endianess. Em Go, não há uma maneira padrão de obter o valor de endianness do processador, e esse valor é necessário para interpretar os bytes corretamente, já que todos os números no struct são do tipo uint32. Esse problema nos deixa com duas opções: usar o package encoding/binary e encontrar uma maneira de obter o valor de endianness do processador, ou ignorar o type system de Go e usar o endereço de buff[0] como o endereço de um unix.InotifyEvent.
Vamos primeiro nos lembrar que endianness é como os bytes de um número são ordenados. Há duas ordens: big-endian, que começa com o most significant byte e termina com o least significant, e little-endian, que é o oposto. Por exemplo, 0x123456 em big-endian fica 12 34 56 e em little-endian fica 56 34 12. Uma maneira de descobrir o valor de endianness do processador é verificando como um número uint16 é armazenado em memória.
func getEndianness() binary.ByteOrder {
n := uint16(1)
firstByte := *((*byte)(unsafe.Pointer(&n)))
if firstByte == 1 {
return binary.LittleEndian
}
return binary.BigEndian
}
Agora que há uma maneira de obter o valor de endianness do processador, o package encoding/binary pode ser usado.
var e unix.InotifyEvent
binary.Read(
bytes.NewReader(buff[:unix.SizeofInotifyEvent]),
getEndianness(),
&e,
)
A segunda opção é menos verbosa e tem a ver com converter o endereço de buff[0] no endereço de um unix.InotifyEvent. Dessa maneira nós não precisamos nos preocupar com endianness.
e := (*unix.InotifyEvent)(unsafe.Pointer(&buff[0]))
O nome
Se você ver a definição de unix.InotifyEvent, você irá perceber que não há um campo para o nome do arquivo/diretório que causou o evento quando um diretório está sendo monitorado, porém há um campo name no struct original (inotify_event). Então, nós tentaremos criar o nosso próprio struct e ver como as coisas se saem.
Esse struct terá o mesmo layout que unix.InotifyEvent, porém com a adição de um campo Name no fim. Nós só precisamos decidir que tipo Name terá. O campo no struct original tem o tipo []char, que representa um flexible array member. Um array de char terminando com NULL é como uma string é representada em C, que é diferente de como uma string é representada em Go. Em Go, uma string é representada por um pointer para seu conteúdo e seu tamanho (length).
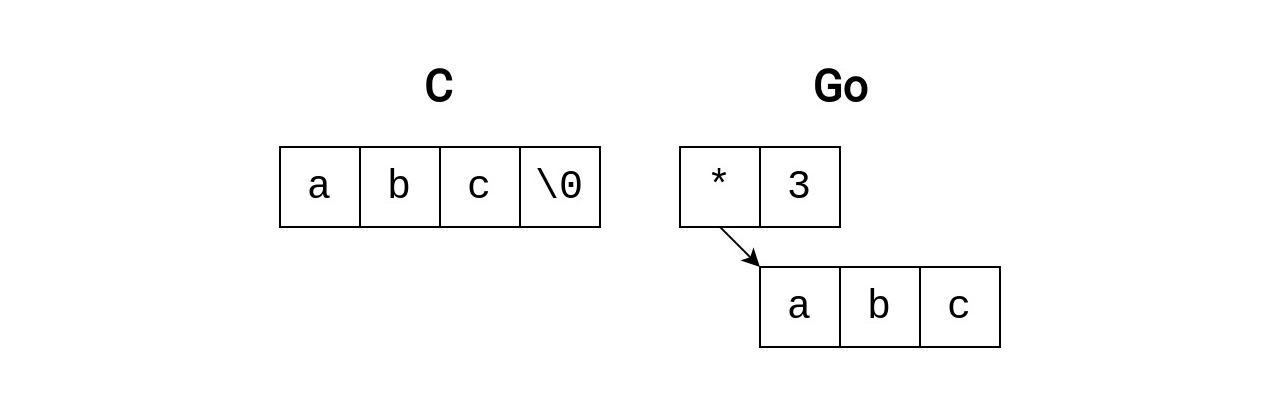
Se nós escolhermos o tipo string, nós não poderemos utilizar a segunda opção para ler eventos devido aos memory layouts entre os structs em C e em Go serem diferentes. A primeira opção também não vai funcionar, já que binary.Read() não aceita um pointer para um struct com um campo de tamanho dinâmico como seu terceiro argumento.
O outro tipo que faz sentido é []byte, mas não vai funcionar com nenhuma das opções de leitura pelas mesmas razões do tipo string. O único tipo restante é um array. Um array de byte tem a mesma representação que []char e um tamanho fixo, porém o problema com um tamanho fixo é que o nome do arquivo/diretório não possui um. Então, nós devemos continuar usando unix.InotifyEvent e encontrar outra maneira de obter o nome.
Há um campo em unix.InotifyEvent que nos diz o tamanho do nome (Len). Nós podemos usar o valor desse campo para obter um slice de buff e convertê-lo em uma string.
name := string(buff[unix.SizeofInotifyEvent:unix.SizeofInotifyEvent+e.Len])
Sim, não é tão verboso. Eu só queria demonstrar o porquê de não haver um campo Name em unix.InotifyEvent.
Caracteres NULL
Ainda há uma coisa a fazer: remover caracteres NULL do fim do nome. Sempre há pelo menos um caractere NULL devido ao nome ser uma string C, mas pode haver mais para garantir requisitos de alinhamento para os próximos itens no buffer. Apesar de os exemplos anteriores assumirem que o buffer tenha apenas um evento, não quer dizer que não possa haver mais.
nameBs := buff[unix.SizeofInotifyEvent : unix.SizeofInotifyEvent+e.Len]
name := string(bytes.TrimRight(nameBs, "\x00"))
Exemplo completo
package main
import (
"bytes"
"fmt"
"log"
"unsafe"
"golang.org/x/sys/unix"
)
func main() {
fd, err := unix.InotifyInit1(0)
if err != nil {
log.Fatalf("err: %v\n", err)
}
defer unix.Close(fd)
_, err = unix.InotifyAddWatch(
fd,
".",
unix.IN_CREATE|
unix.IN_DELETE|
unix.IN_CLOSE_WRITE|
unix.IN_MOVED_TO|
unix.IN_MOVED_FROM|
unix.IN_MOVE_SELF,
)
if err != nil {
log.Fatalf("err: %v\n", err)
}
var buff [(unix.SizeofInotifyEvent + unix.NAME_MAX + 1) * 20]byte
for {
offset := 0
n, err := unix.Read(fd, buff[:])
if err != nil {
log.Fatalf("err: %v\n", err)
}
for offset < n {
e := (*unix.InotifyEvent)(unsafe.Pointer(&buff[offset]))
nameBs := buff[offset+unix.SizeofInotifyEvent : offset+unix.SizeofInotifyEvent+int(e.Len)]
name := string(bytes.TrimRight(nameBs, "\x00"))
if len(name) > 0 && e.Mask&unix.IN_ISDIR == unix.IN_ISDIR {
name += " (dir)"
}
switch {
case e.Mask&unix.IN_CREATE == unix.IN_CREATE:
fmt.Printf("CREATE %v\n", name)
case e.Mask&unix.IN_DELETE == unix.IN_DELETE:
fmt.Printf("DELETE %v\n", name)
case e.Mask&unix.IN_CLOSE_WRITE == unix.IN_CLOSE_WRITE:
fmt.Printf("CLOSE_WRITE %v\n", name)
case e.Mask&unix.IN_MOVED_TO == unix.IN_MOVED_TO:
fmt.Printf("IN_MOVED_TO [%v] %v\n", e.Cookie, name)
case e.Mask&unix.IN_MOVED_FROM == unix.IN_MOVED_FROM:
fmt.Printf("IN_MOVED_FROM [%v] %v\n", e.Cookie, name)
case e.Mask&unix.IN_MOVE_SELF == unix.IN_MOVE_SELF:
fmt.Printf("IN_MOVE_SELF %v\n", name)
}
offset += int(unix.SizeofInotifyEvent + e.Len)
}
}
}
Referências
Aqui tem uma lista de links que eu usei como referências e/ou estendem o que eu falei sobre alguns conceitos:
- http://man7.org/linux/man-pages/man7/inotify.7.html
- https://developer.ibm.com/technologies/systems/articles/au-endianc/
- https://www.gnu.org/software/libc/manual/html_node/Limits-for-Files.html
- http://blog.golang.org/slices-intro
- https://blog.golang.org/strings
- https://blog.golang.org/slices
- https://research.swtch.com/godata
- http://inotify.aiken.cz/
- https://wr.informatik.uni-hamburg.de/_media/teaching/wintersemester_2013_2014/epc-14-haase-svenhendrik-alignmentinc-paper.pdf